Pesquisador do C3SL e reitor eleito da UFPR, Sunye participou de atividade do TJ-PR, que está investindo em IA no Judiciário.
No último dia 31 de outubro, o Tribunal de Justiça do Paraná (TJ-PR) celebrou um contrato com a Microsoft por meio do qual adotará a Inteligência Artificial Copilot no cotidiano da instituição, para melhorar a eficiência do Judiciário. Pesquisador do Centro de Computação Científica e Software Livre (C3SL) e reitor eleito da Universidade Federal do Paraná (UFPR), Marcos Sunye foi convidado a falar no evento e elogiou a iniciativa de pôr o TJ-PR em linha com o que há de moderno na administração pública.
Sunye convidou os magistrados a refletirem no impacto positivo dessas novas tecnologias, ao mesmo tempo em que pediu para os membros do Tribunal de Justiça do Paraná sonharem com o desenvolvimento de uma Inteligência Artificial “nativa”, cujo parque tecnológico esteja aqui e tenha sido desenvolvido por pesquisadores do estado, “para atender às nossas demandas, com a nossa linguagem”. O reitor eleito da UFPR contou que esteve, na véspera, no Ministério da Agricultura, para atrair para o Paraná a criação do Centro Nacional de IA para o Agronegócio.
“O agronegócio pode se beneficiar largamente do uso de IA para aumento da produtividade, assim como o serviço público pode melhorar sua eficiência administrativa com a automação das tarefas mais simples”, concordou Sunye, que há 20 fundou o C3SL. Hoje, o Centro de Computação Científica é parte importante da execução de políticas dos ministérios da Educação e da Saúde, com foco na soberania nacional. O TJ-PR adquiriu 1.600 licenças do Copilot.
A palestra realizada pelo pesquisador Eduardo Todt destaca como técnicas de Inteligência melhoram o reconhecimento de fontes em jornais brasileiros durante a III Conferência Internacional em Aplicações de Inteligência Artificial
O uso de inteligência artificial no reconhecimento de fontes de caracteres em análise e digitalização de jornais históricos brasileiros em alemão foi o tema da palestra do pesquisador do Centro de Computação Científica e Software Livre (C3SL) e professor de Departamento de Informática da UFPR, Eduardo Todt, na III Conferência Internacional em Aplicações de Inteligência Artificial (CINTIA). O evento foi realizado na Universidad Tecnológica del Uruguay (Utec), entre os dias 8 e 10 de outubro. A palestra em formato remoto integrou a programação do evento, que reuniu pesquisadores e profissionais da área de tecnologia para discutir a utilização da Inteligência Artificial (IA) na solução de problemas em diversas áreas.
No evento, Todt apresentou a aplicação de machine learning no projeto Deutschsprachige Presse in Brasilien, que busca aplicar técnicas avançadas de reconhecimento óptico de caracteres (OCR) utilizando redes neurais profundas, como ResNet e VRR19. Realizado pelo Laboratório Visão Robótica e Imagem (VRI) em parceria com o C3SL e o Departamento de Polonês, Alemão e Letras Clássicas da UFPR, o projeto faz parte do acordo de cooperação firmado entre a UFPR e a Academia de Ciências de Berlim-Brandemburgo.
A imigração alemã no Brasil, que completa 200 anos, deixou um legado cultural significativo, refletido em jornais editados entre 1824 e 1930. No entanto, a mera digitalização dessas publicações não é suficiente. Segundo Todt, “se os jornais forem apenas escaneados e disponibilizados online, pesquisadores terão que ler imagens, o que não é produtivo”. A falta de um sistema eficiente para converter essas imagens em texto pesquisável limita a investigação acadêmica e histórica. Além disso, a complexidade das publicações dos jornais, com diversos tipos de caracteres, clichês e diagramações, prejudica o desempenho da digitalização, sendo um obstáculo para o OCR.
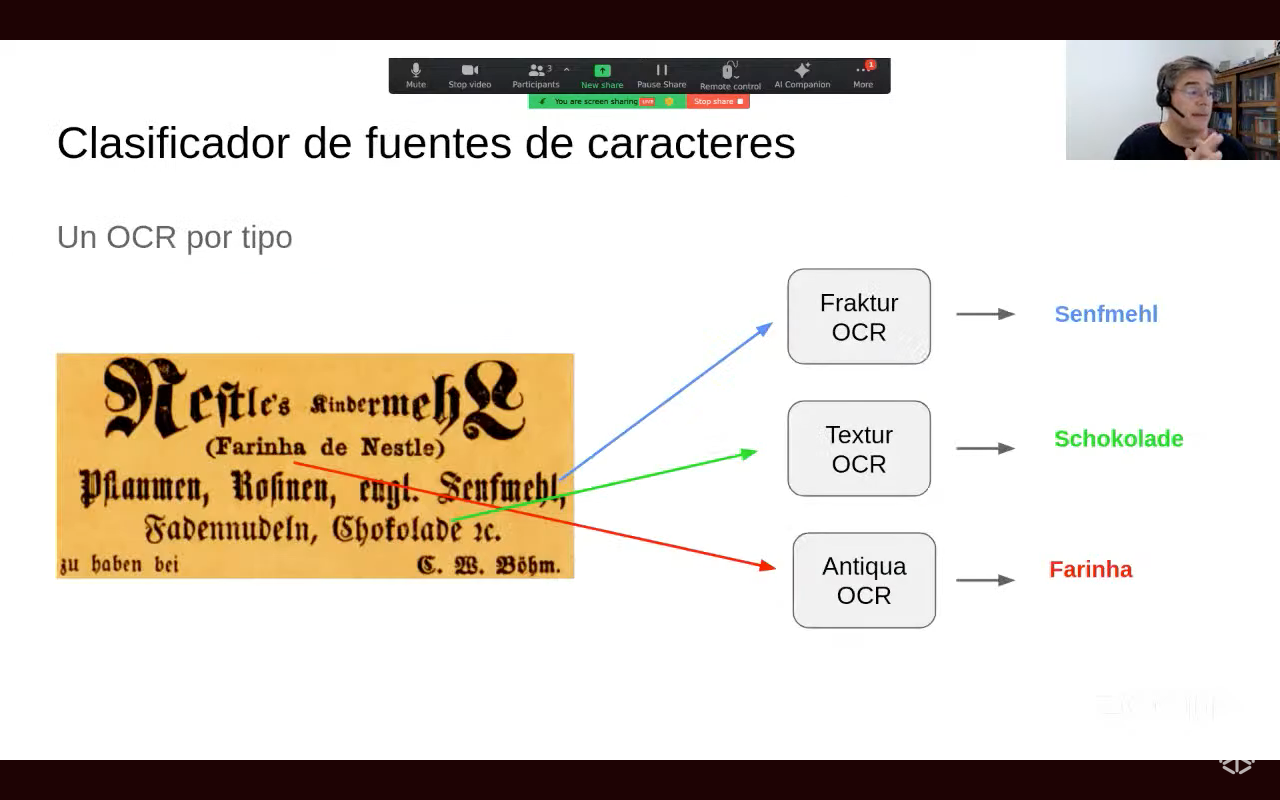
De acordo com Todt, tanto a multiplicidade de estilos de fontes de caracteres usadas nos jornais quanto a diversidade de layouts prejudicam as transcrições automáticas, resultando em má interpretação dos conteúdos pelos sistemas, ou ainda na omissão de informações. É neste aspecto que o uso de inteligência artificial auxilia no processo de escaneamento e de análise dos documentos. A proposta com o uso de inteligência artificial no projeto é de estruturar um fluxo de processamento de dados que mescla tanto análise semântica quanto a identificação dos caracteres e formatos de fontes.
Até agora, o projeto já escaneou cerca de 6 mil páginas de jornais e obteve mais de dez mil amostras segmentadas semi-automaticamente. Com um dataset robusto criado para treinamento das redes neurais, os resultados preliminares mostram uma precisão nas classificações que varia entre 98% e quase 100%. “Agora temos nosso classificador dos tipos das fontes dos caracteres! Essa parte integra nosso fluxo visando tornar o OCR mais inteligente, adaptando-se ao desafio apresentado pelos jornais com múltiplos estilos diferentes no mesmo texto onde os sistemas tradicionais falham”, conclui o pesquisador. Clique aqui e confira na íntegra a apresentação do professor no evento >> https://www.youtube.com/live/EBDLEFHrQHQ?si=GONU0TtX6CP0v2q9&t=20780